面试篇-Sentinel源码分析
1. Sentinel的基本概念
Sentinel实现限流、隔离、降级、熔断等功能,本质要做的就是两件事情:
统计数据:统计某个资源的访问数据(QPS、RT等信息)
规则判断:判断限流规则、隔离规则、降级规则、熔断规则是否满足
这里的资源就是希望被Sentinel保护的业务,例如项目中定义的controller方法就是默认被Sentinel保护的资源。
1.1 ProcessorSlotChain
实现上述功能的核心骨架是一个叫做ProcessorSlotChain的类。这个类基于责任链模式来设计,将不同的功能(限流、降级、系统保护)封装为一个个的Slot,请求进入后逐个执行即可。
其工作流如图:

责任链中的Slot也分为两大类:
统计数据构建部分(statistic)
NodeSelectorSlot:负责构建簇点链路中的节点(DefaultNode),将这些节点形成链路树
ClusterBuilderSlot:负责构建某个资源的ClusterNode,ClusterNode可以保存资源的运行信息(响应时间、QPS、block 数目、线程数、异常数等)以及来源信息(origin名称)
StatisticSlot:负责统计实时调用数据,包括运行信息、来源信息等
规则判断部分(rule checking)
AuthoritySlot:负责授权规则(来源控制)
SystemSlot:负责系统保护规则
ParamFlowSlot:负责热点参数限流规则
FlowSlot:负责限流规则
DegradeSlot:负责降级规则
1.2 Node
Sentinel中的簇点链路是由一个个的Node组成的,Node是一个接口,包括下面的实现:

所有的节点都可以记录对资源的访问统计数据,所以都是StatisticNode的子类。
按照作用分为两类Node:
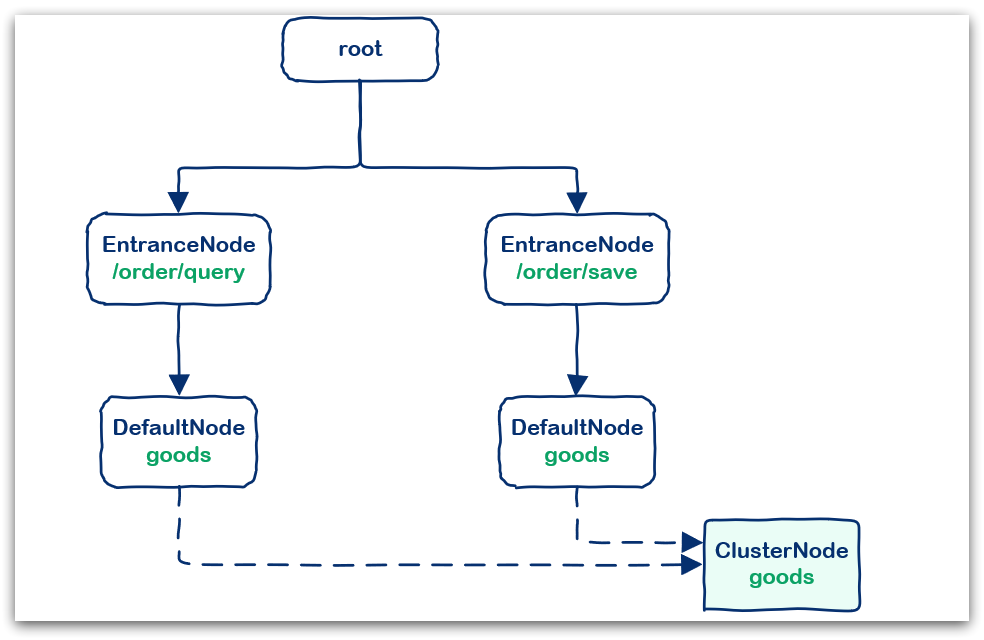
DefaultNode:代表链路树中的每一个资源,一个资源出现在不同链路中时,会创建不同的DefaultNode节点。而树的入口节点叫EntranceNode,是一种特殊的DefaultNode
ClusterNode:代表资源,一个资源不管出现在多少链路中,只会有一个ClusterNode。记录的是当前资源被访问的所有统计数据之和。
DefaultNode记录的是资源在当前链路中的访问数据,用来实现基于链路模式的限流规则。ClusterNode记录的是资源在所有链路中的访问数据,实现默认模式、关联模式的限流规则。
例如:我们在一个SpringMVC项目中,有两个业务:
业务1:controller中的资源
/order/query访问了service中的资源/goods业务2:controller中的资源
/order/save访问了service中的资源/goods
创建的链路图如下:
1.3 Entry
默认情况下,Sentinel会将controller中的方法作为被保护资源,那么问题来了,我们该如何将自己的一段代码标记为一个Sentinel的资源呢?
Sentinel中的资源用Entry来表示。声明Entry的API示例:
1.3.1 自定义资源
例如,我们在order-service服务中,将OrderService的queryOrderById()方法标记为一个资源。
1)首先在order-service中引入sentinel依赖
2)然后配置Sentinel地址
3)修改OrderService类的queryOrderById方法
代码这样来实现:
4)访问
打开浏览器,访问order服务:http://localhost:8080/order/101
然后打开sentinel控制台,查看簇点链路:

1.3.2 基于注解标记资源
在之前学习Sentinel的时候,我们知道可以通过给方法添加@SentinelResource注解的形式来标记资源。

这个是怎么实现的呢?
来看下我们引入的Sentinel依赖包:

其中的spring.factories声明需要就是自动装配的配置类,内容如下:

我们来看下SentinelAutoConfiguration这个类:

可以看到,在这里声明了一个Bean,SentinelResourceAspect:
简单来说,@SentinelResource注解就是一个标记,而Sentinel基于AOP思想,对被标记的方法做环绕增强,完成资源(Entry)的创建。
1.4 Context
上一节,我们发现簇点链路中除了controller方法、service方法两个资源外,还多了一个默认的入口节点:
sentinel_spring_web_context,是一个EntranceNode类型的节点
这个节点是在初始化Context的时候由Sentinel帮我们创建的。
1.4.1 什么是Context
那么,什么是Context呢?
Context 代表调用链路上下文,贯穿一次调用链路中的所有资源(
Entry),基于ThreadLocal。Context 维持着入口节点(
entranceNode)、本次调用链路的 curNode(当前资源节点)、调用来源(origin)等信息。后续的Slot都可以通过Context拿到DefaultNode或者ClusterNode,从而获取统计数据,完成规则判断
Context初始化的过程中,会创建EntranceNode,contextName就是EntranceNode的名称
对应的API如下:
1.4.2 Context的初始化
那么这个Context又是在何时完成初始化的呢?
1.4.2.1 自动装配
来看下我们引入的Sentinel依赖包:
其中的spring.factories声明需要就是自动装配的配置类,内容如下:
我们先看SentinelWebAutoConfiguration这个类:

这个类实现了WebMvcConfigurer,我们知道这个是SpringMVC自定义配置用到的类,可以配置HandlerInterceptor:
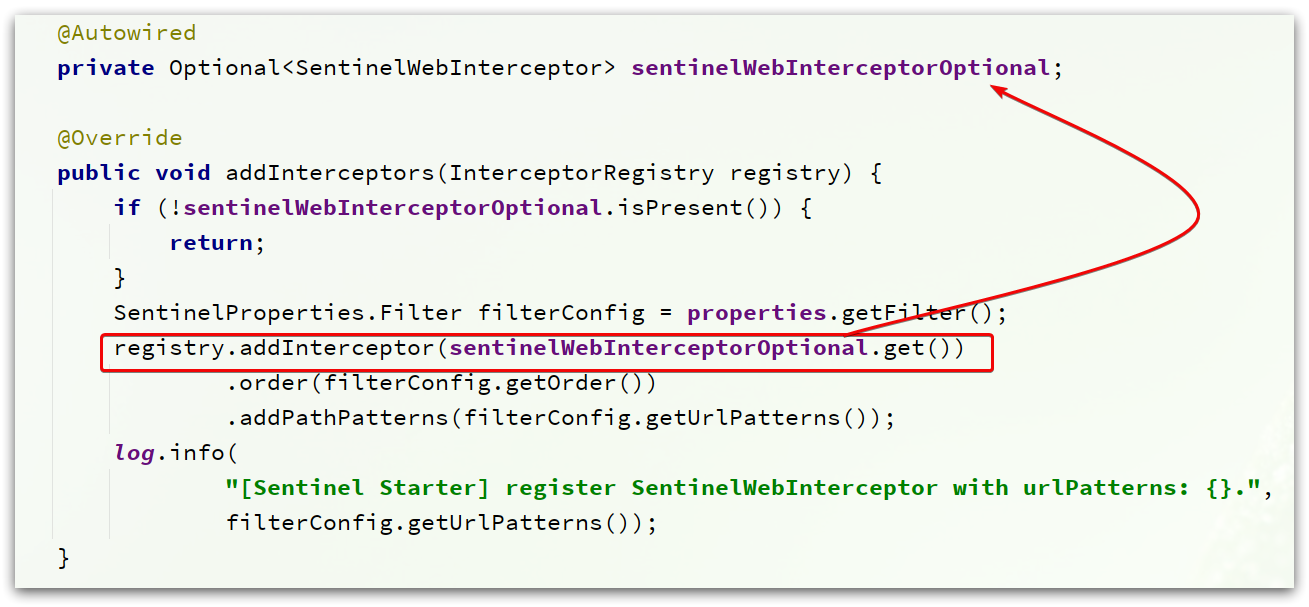
可以看到这里配置了一个SentinelWebInterceptor的拦截器。
SentinelWebInterceptor的声明如下:

发现它继承了AbstractSentinelInterceptor这个类。
HandlerInterceptor拦截器会拦截一切进入controller的方法,执行preHandle前置拦截方法,而Context的初始化就是在这里完成的。
1.4.2.2 AbstractSentinelInterceptor
HandlerInterceptor拦截器会拦截一切进入controller的方法,执行preHandle前置拦截方法,而Context的初始化就是在这里完成的。
我们来看看这个类的preHandle实现:
1.4.2.3 ContextUtil
创建Context的方法就是 ContextUtil.enter(contextName, origin);
我们进入该方法:
进入trueEnter方法:
2. ProcessorSlotChain执行流程
接下来我们跟踪源码,验证下ProcessorSlotChain的执行流程。
2.1 入口
首先,回到一切的入口,AbstractSentinelInterceptor类的preHandle方法:
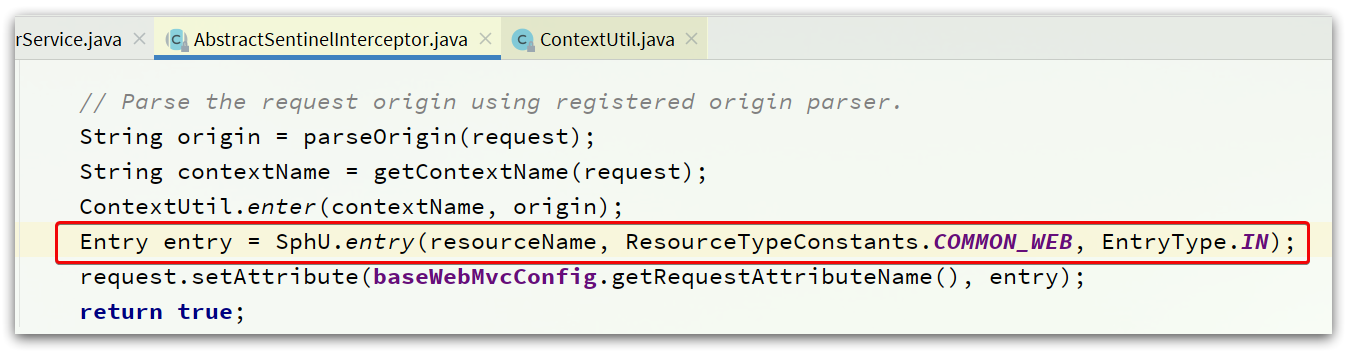
还有,SentinelResourceAspect的环绕增强方法:

可以看到,任何一个资源必定要执行SphU.entry()这个方法:
继续进入Env.sph.entryWithType(name, resourceType, trafficType, 1, args);:
进入entryWithPriority方法:
在这段代码中,会获取ProcessorSlotChain对象,然后基于chain.entry()开始执行slotChain中的每一个Slot. 而这里创建的是其实现类:DefaultProcessorSlotChain.
获取ProcessorSlotChain以后会保存到一个Map中,key是ResourceWrapper,值是ProcessorSlotChain.
所以,一个资源只会有一个ProcessorSlotChain.
2.2 DefaultProcessorSlotChain
我们进入DefaultProcessorSlotChain的entry方法:
这里的first,类型是AbstractLinkedProcessorSlot:

看下继承关系:

因此,first一定是这些实现类中的一个,按照最早讲的责任链顺序,first应该就是 NodeSelectorSlot。
不过,既然是基于责任链模式,所以这里只要记住下一个slot就可以了,也就是next:

next确实是NodeSelectSlot类型。
而NodeSelectSlot的next一定是ClusterBuilderSlot,依次类推:

责任链就建立起来了。
2.3. NodeSelectorSlot
NodeSelectorSlot负责构建簇点链路中的节点(DefaultNode),将这些节点形成链路树。
核心代码:
这个Slot完成了这么几件事情:
为当前资源创建 DefaultNode
将DefaultNode放入缓存中,key是contextName,这样不同链路入口的请求,将会创建多个DefaultNode,相同链路则只有一个DefaultNode
将当前资源的DefaultNode设置为上一个资源的childNode
将当前资源的DefaultNode设置为Context中的curNode(当前节点)
下一个slot,就是ClusterBuilderSlot
2.4 ClusterBuilderSlot
ClusterBuilderSlot负责构建某个资源的ClusterNode,核心代码:
2.5 StatisticSlot
StatisticSlot负责统计实时调用数据,包括运行信息(访问次数、线程数)、来源信息等。
StatisticSlot是实现限流的关键,其中基于滑动时间窗口算法维护了计数器,统计进入某个资源的请求次数。
核心代码:
另外,需要注意的是,所有的计数+1动作都包括两部分,以 node.addPassRequest(count);为例:
具体计数方式,我们后续再看。
接下来,进入规则校验的相关slot了,依次是:
AuthoritySlot:负责授权规则(来源控制)
SystemSlot:负责系统保护规则
ParamFlowSlot:负责热点参数限流规则
FlowSlot:负责限流规则
DegradeSlot:负责降级规则
2.6 AuthoritySlot
负责请求来源origin的授权规则判断,如图:
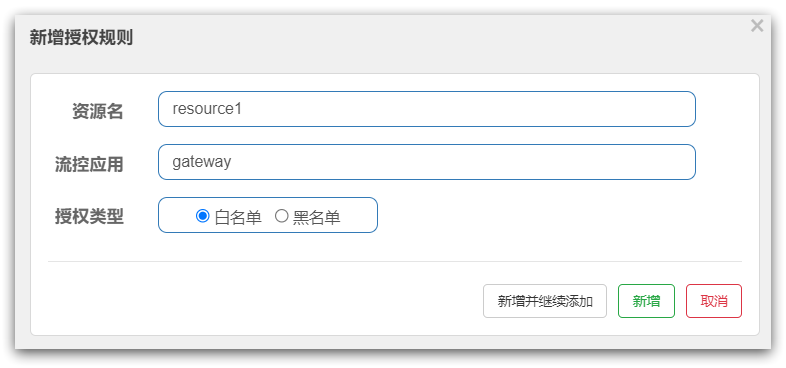
核心API:
黑白名单校验的逻辑:
再看下AuthorityRuleChecker.passCheck(rule, context)方法:
2.7 SystemSlot
SystemSlot是对系统保护的规则校验:

核心API:
来看下SystemRuleManager.checkSystem(resourceWrapper);的代码:
2.8 ParamFlowSlot
ParamFlowSlot就是热点参数限流,如图:
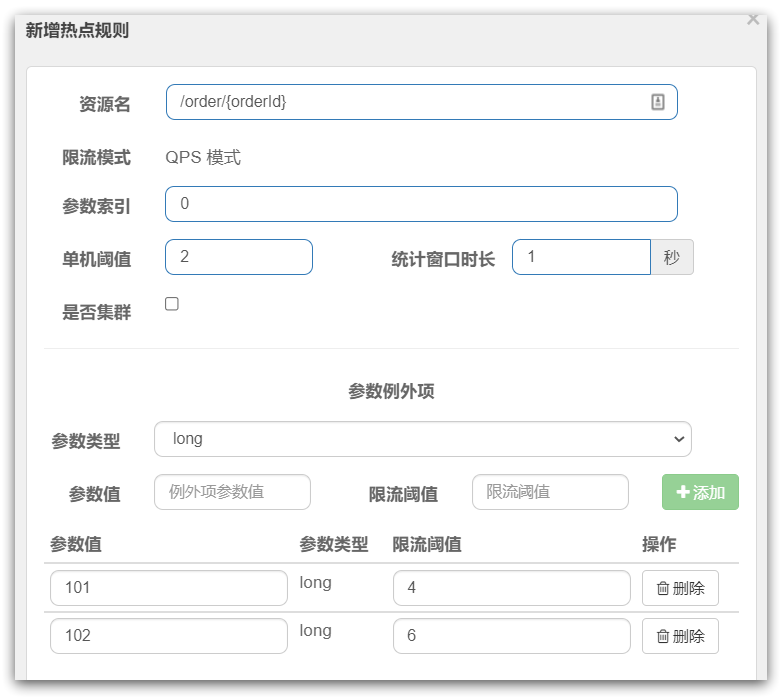
是针对进入资源的请求,针对不同的请求参数值分别统计QPS的限流方式。
这里的单机阈值,就是最大令牌数量:maxCount
这里的统计窗口时长,就是统计时长:duration
含义是每隔duration时间长度内,最多生产maxCount个令牌,上图配置的含义是每1秒钟生产2个令牌。
核心API:
2.8.1 令牌桶
热点规则判断采用了令牌桶算法来实现参数限流,为每一个不同参数值设置令牌桶,Sentinel的令牌桶有两部分组成:

这两个Map的key都是请求的参数值,value却不同,其中:
tokenCounters:用来记录剩余令牌数量
timeCounters:用来记录上一个请求的时间
当一个携带参数的请求到来后,基本判断流程是这样的:

2.9 FlowSlot
FlowSlot是负责限流规则的判断,如图:

包括:
三种流控模式:直接模式、关联模式、链路模式
三种流控效果:快速失败、warm up、排队等待
三种流控模式,从底层数据统计角度,分为两类:
对进入资源的所有请求(ClusterNode)做限流统计:直接模式、关联模式
对进入资源的部分链路(DefaultNode)做限流统计:链路模式
三种流控效果,从限流算法来看,分为两类:
滑动时间窗口算法:快速失败、warm up
漏桶算法:排队等待效果
2.9.1 核心流程
核心API如下:
checkFlow方法:
跟入FlowRuleChecker:
这里的FlowRule就是限流规则接口,其中的几个成员变量,刚好对应表单参数:
校验的逻辑定义在FlowRuleChecker的canPassCheck方法中:
进入passLocalCheck():
这里对规则的判断先要通过FlowRule#getRater()获取流量控制器TrafficShapingController,然后再做限流。
而TrafficShapingController有3种实现:

DefaultController:快速失败,默认的方式,基于滑动时间窗口算法
WarmUpController:预热模式,基于滑动时间窗口算法,只不过阈值是动态的
RateLimiterController:排队等待模式,基于漏桶算法
最终的限流判断都在TrafficShapingController的canPass方法中。
2.9.2 滑动时间窗口
滑动时间窗口的功能分两部分来看:
一是时间区间窗口的QPS计数功能,这个是在StatisticSlot中调用的
二是对滑动窗口内的时间区间窗口QPS累加,这个是在FlowRule中调用的
先来看时间区间窗口的QPS计数功能。
2.9.2.1 时间窗口请求量统计
回顾2.5章节中的StatisticSlot部分,有这样一段代码:

就是在统计通过该节点的QPS,我们跟入看看,这里进入了DefaultNode内部:

发现同时对DefaultNode和ClusterNode在做QPS统计,我们知道DefaultNode和ClusterNode都是StatisticNode的子类,这里调用addPassRequest()方法,最终都会进入StatisticNode中。
随便跟入一个:

这里有秒、分两种纬度的统计,对应两个计数器。找到对应的成员变量,可以看到:

两个计数器都是ArrayMetric类型,并且传入了两个参数:
如图:
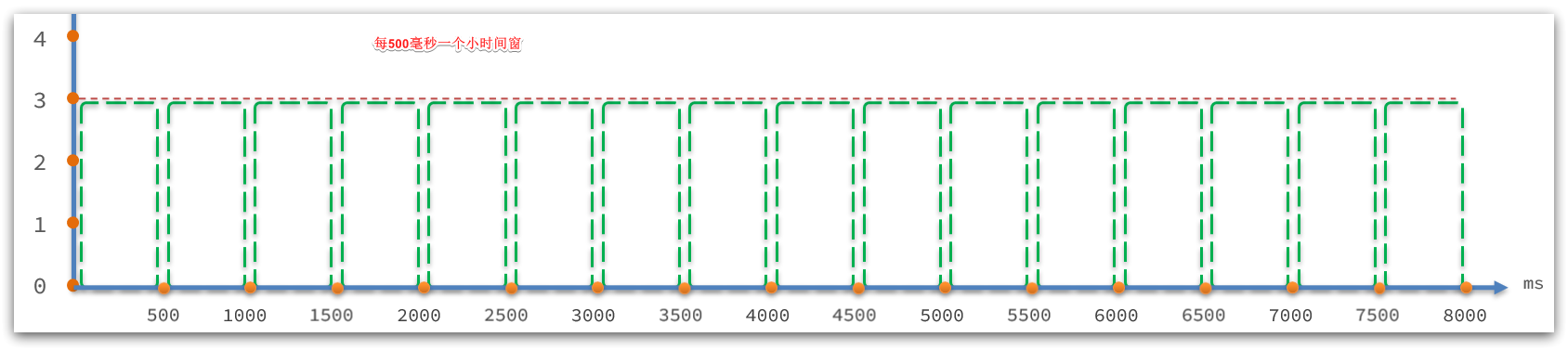
接下来,我们进入ArrayMetric类的addPass方法:
那么,计数器如何知道当前所在的窗口是哪个呢?
这里的data是一个LeapArray:

LeapArray的四个属性:
LeapArray是一个环形数组,因为时间是无限的,数组长度不可能无限,因此数组中每一个格子放入一个时间窗(window),当数组放满后,角标归0,覆盖最初的window。

因为滑动窗口最多分成sampleCount数量的小窗口,因此数组长度只要大于sampleCount,那么最近的一个滑动窗口内的2个小窗口就永远不会被覆盖,就不用担心旧数据被覆盖的问题了。
我们跟入 data.currentWindow();方法:
找到当前时间所在窗口(WindowWrap)后,只要调用WindowWrap对象中的add方法,计数器+1即可。
这里只负责统计每个窗口的请求量,不负责拦截。限流拦截要看FlowSlot中的逻辑。
2.9.2.2 滑动窗口QPS计算
在2.9.1小节我们讲过,FlowSlot的限流判断最终都由TrafficShapingController接口中的canPass方法来实现。该接口有三个实现类:
DefaultController:快速失败,默认的方式,基于滑动时间窗口算法
WarmUpController:预热模式,基于滑动时间窗口算法,只不过阈值是动态的
RateLimiterController:排队等待模式,基于漏桶算法
因此,我们跟入默认的DefaultController中的canPass方法来分析:
因此,判断的关键就是int curCount = avgUsedTokens(node);
因为我们采用的是限流,走node.passQps()逻辑:
那么rollingCounterInSecond.pass()是如何得到请求量的呢?
来看看data.values()如何获取 滑动窗口范围内 的所有小窗口:
那么,isWindowDeprecated(timeMillis, windowWrap)又是如何判断窗口是否符合要求呢?
2.9.3 漏桶
上一节我们讲过,FlowSlot的限流判断最终都由TrafficShapingController接口中的canPass方法来实现。该接口有三个实现类:
DefaultController:快速失败,默认的方式,基于滑动时间窗口算法
WarmUpController:预热模式,基于滑动时间窗口算法,只不过阈值是动态的
RateLimiterController:排队等待模式,基于漏桶算法
因此,我们跟入默认的RateLimiterController中的canPass方法来分析:
与我们之前分析的漏桶算法基本一致:

2.10 DegradeSlot
最后一关,就是降级规则判断了。
Sentinel的降级是基于状态机来实现的:
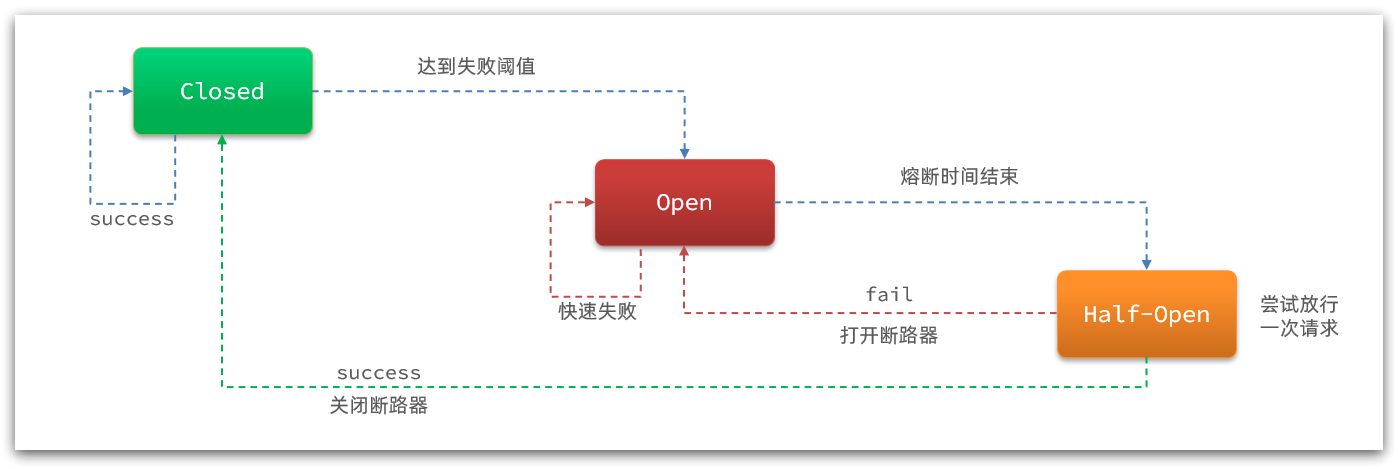
对应的实现在DegradeSlot类中,核心API:
继续进入performChecking方法:
2.10.1 CircuitBreaker
我们进入CircuitBreaker的tryPass方法中:
有关时间窗的判断在retryTimeoutArrived()方法:
OPEN到HALF_OPEN切换在fromOpenToHalfOpen(context)方法:
这里出现了从OPEN到HALF_OPEN、从HALF_OPEN到OPEN的变化,但是还有几个没有:
从CLOSED到OPEN
从HALF_OPEN到CLOSED
2.10.2 触发断路器
请求经过所有插槽 后,一定会执行exit方法,而在DegradeSlot的exit方法中:

会调用CircuitBreaker的onRequestComplete方法。而CircuitBreaker有两个实现:

我们这里以异常比例熔断为例来看,进入ExceptionCircuitBreaker的onRequestComplete方法:
来看阈值判断的方法:
Last updated